Vernetzte Daten: Graphdatenbanken
Immer wieder werden relationale Datenbanken für Datenstukturen gewählt, die stark vernetzt sind. Graphdatenbanken sind schneller und einfacher wenn es darum geht vernetzte Strukturen abzubilden. Abfragen die tief in die Struktur eindringen sind deutlich schneller und kompliziertes ORM (objektrelationales Mapping) entfällt. Ein Beispiel eines kleinen sozialen Netzwerks zeigt, wie Graphdatenbanken das Leben eines Entwicklers erleichtern und viele Abfragen erheblich beschleunigen.
Die lieben Daten
Relationale Datenbanken eignen sich sehr gut für tabellarische Daten. Was aber, wenn Daten nicht tabellarisch sind sondern stark miteinander vernetzt?

Folgendes sind Beispiele für stark vernetzte Daten.
Netzwerke wie beispielsweise:
- Hardwarenetze
- soziale Netzwerke
- das Internet
- Verkehrsnetze
- geografische Daten
- Wortnetze/Ontologien
Baumstrukturen wie beispielsweise:
- ein Familienstammbaum
- eine Firmenhierarchie
Beispiel: (Mini) soziales Netzwerk
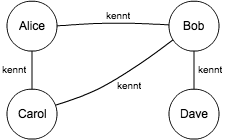
Angenommen wir möchten die 4 abgebildeten Personen und deren Bekanntschaften modellieren. Unser Ziel ist es, Personen zu finden die Alice nicht kennt aber eine ihrer Bekanntschaften. Im Beispiel ist die Antwort einfach: Dave.
Bei vielen weiteren Personen und Bekanntschaften wird man allerdings schnell die Übersicht verlieren (siehe erstes Bild). Darum wollen wir eine Datenstruktur entwickeln, die uns das Finden von unbekannten Personen abnimmt.
Der relationale Weg
Relationale Datenbanken speichern Daten in Form von Tabellen. Unser Beispiel müssen wir in diese Tabellenform bringen – das ORM (objektrelationales Mapping).

Die Tabelle “users” enthält eine Liste der Namen sowie jeweils eine eindeutige Identifikationsnummer “id”. Die Hilfstabelle “users_knows” verbindet zwei Personen anhand ihrer Identifikationsnummer “user_id” und ”known_user_id”.
Der Graph-Weg
Graphdatenbanken speichern Daten in Form von Graph-Strukturen. Ein Graph bestehet aus beliebig vielen Knoten und Kanten. Ein Knoten kann beliebig viele Kanten (Verbindungen) zu Knoten haben. Sowohl Knoten als auch Kanten können Eigenschaften besitzen.
Was müssen wir also tun um unser Beispiel in einer Graphdatenbank zu speichern? Nichts… Jede Person entspricht einem Knoten mit dem Namen (Alice, Bob und so weiter) als Knoten-Eigenschaft “name”. Kennt eine Person eine andere wird eine Kante zwischen den entsprechenden Knoten gezogen. Ein ORM entfällt.
Warum Graphdatenbanken schneller sind
Die Suche nach einer Person über einen Index (meist B-Baum) ist mit der Laufzeit O(log(n)) möglich.
Bei einer relationalen Datenbank müssen wir also zuerst die ID von Alice finden. Das kostet uns O(log(n)). Dann müssen wir die IDs der Bekanntschaften von Alice finden – ebenfalls in O(log(n)). Die IDs der Bekanntschaften der gefundenen Bekanntschaften kosten wieder O(log(n)) und letztendlich möchten wir die Namen der unbekannten Personen herausfinden was ebenfalls wieder in O(log(n)) möglich ist.
Verwenden wir eine Graphstruktur benötigen wir nur für das Finden des Alice-Knotens eine Laufzeit von O(log(n)). Alle weiteren Abfragen sind in O(k) wobei k für die Anzahl der Bekanntschaften steht.
Quellen und weiterführendes Material
- Emil Eifrem über Graphdatenbanken (Youtube video)
- Marko Rodriguez über Problem-Solving using Graph Traversals: Searching, Scoring, Ranking, and Recommendation (Präsentation)
- Opensource Graph-Visualisierung und Bearbeitungssoftware: Gephi